-
[주간학습 정리] Week 5Naver AI Tech 2024. 9. 6. 17:33
강의 내용 중 인상깊었던 'Data Attribution'에 대해서 몇가지 간단하게 내용 작성하였다
Data Attribution
- 모델의 예측에 관하여 어떤 입력 데이터가 얼마나 기여했는지 분석하고 해석하는 과정
- 인공지능의 설명 가능성(Explainable)과 관련있다
Influence function
- 특정 데이터 포인트가 모델이나 추정치에 미치는 영향을 측정하는 도구
- 데이터셋에서 하나의 샘플을 제거하거나 가중치를 변경했을때 모델 파라미터나 예측에 미치는 영향을 측정한다
- 모델의 해석가능성을 높이고 영향력 있는 데이터 포인트를 식별하며 모델 디버깅에 활용된다
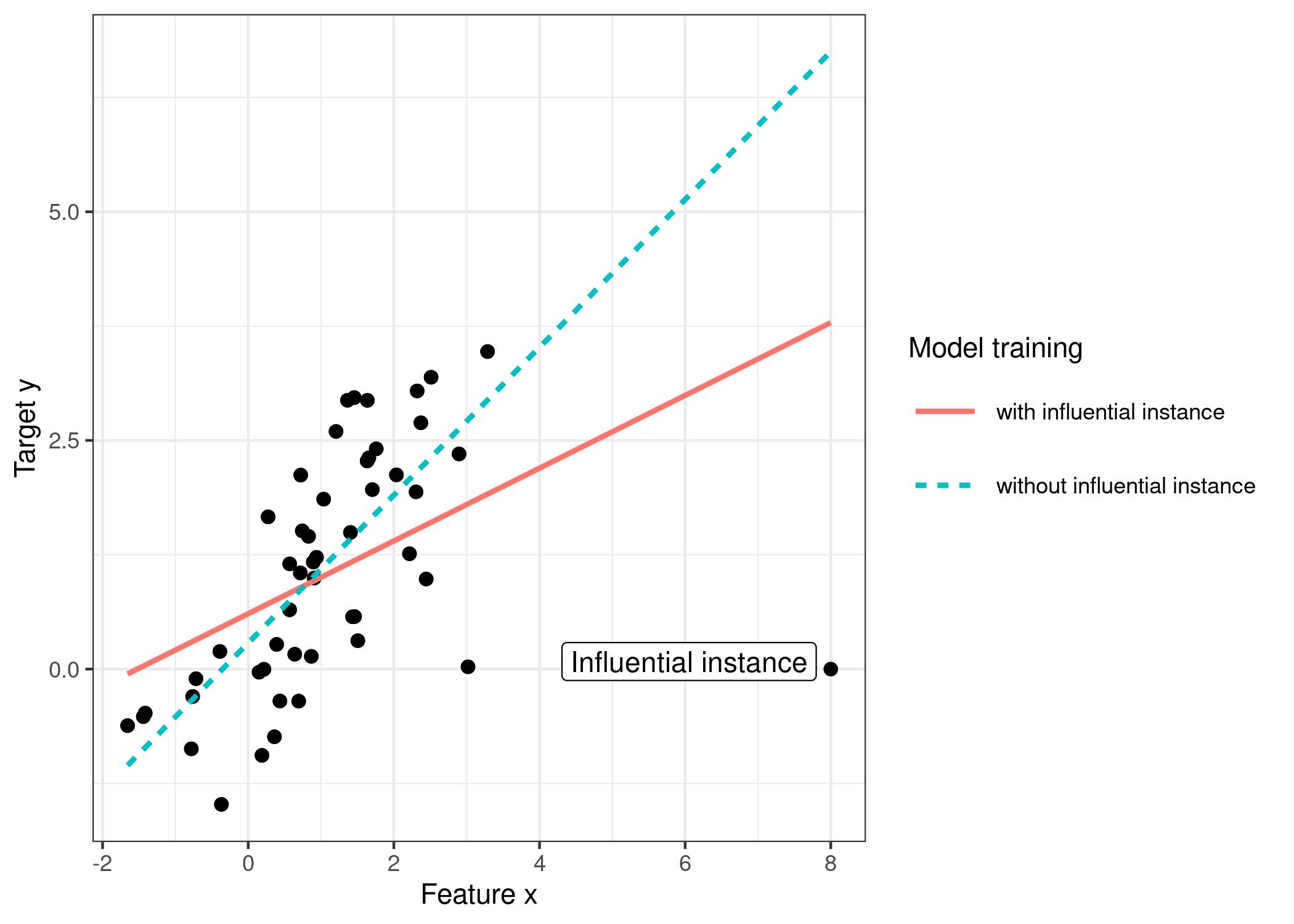
FIGURE 10.17: A linear model with one feature. Trained once on the full data and once without the influential instance. Removing the influential instance changes the fitted slope (weight/coefficient) drastically. - 이미지 출처: https://christophm.github.io/interpretable-ml-book/influential.html
추천 시스템에서 influence function 활용
- 영향력 있는 사용자 식별이 가능하다. 특정 아이템에 대한 추천에 가장 큰 영향을 미친 사용자들을 파악할 수 있다.
- 추천 정확도를 개선할 수 있다. 영향력 있는 데이터 포인트를 식별하여 노이즈가 있는 데이터를 제거하거나 재가중치를 부여할 수 있다.
- 개인화를 강화할 수 있다. 각 사용자에게 가장 영향을 미치는 데이터 포인트를 파악하여 더 개인화된 추천을 제공할 수 있다.
- 콜드 스타트 문제 해결에 도움이 된다. 새로운 사용자나 아이템에 대해 영향력 있는 기존 데이터를 활용하여 초기 추천을 개선할 수 있다.
- 설명 가능한 추천을 제공할 수 있다. 특정 추천 결과에 대해 가장 영향을 준 데이터 포인트를 제시함으로써 추천 이유를 설명할 수 있다.
- 데이터셋 오류를 탐지할 수 있다. 추천에 부정적인 영향을 미치는 데이터를 식별하여 데이터셋의 품질을 개선할 수 있다.
알고리즘
1. Data Shapley
- 협력 게임 이론의 Shapley value 개념을 데이터 가치 평가에 적용한 방법이다.
- 각 데이터 포인트가 모델 성능에 기여하는 정도를 수치화한다.
- 공정성, 효율성 등 바람직한 특성을 만족하는 유일한 데이터 가치 평가 방식이다.
- 계산 복잡도가 높아 대규모 데이터셋에는 근사 알고리즘을 사용한다.
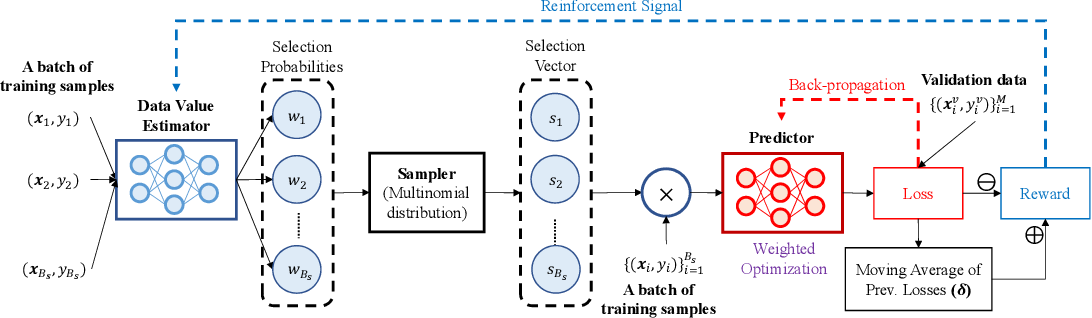
2. DVRL(Data Valuation using Reinforcement Learning)
- 강화학습을 사용하여 데이터의 가치를 평가하는 방법이다.
- 데이터 선택을 순차적 의사결정 문제로 모델링한다.
- 강화학습 에이전트가 데이터 포인트의 가치를 학습하고 선택한다.
- Data Shapley에 비해 계산 효율성이 높다.
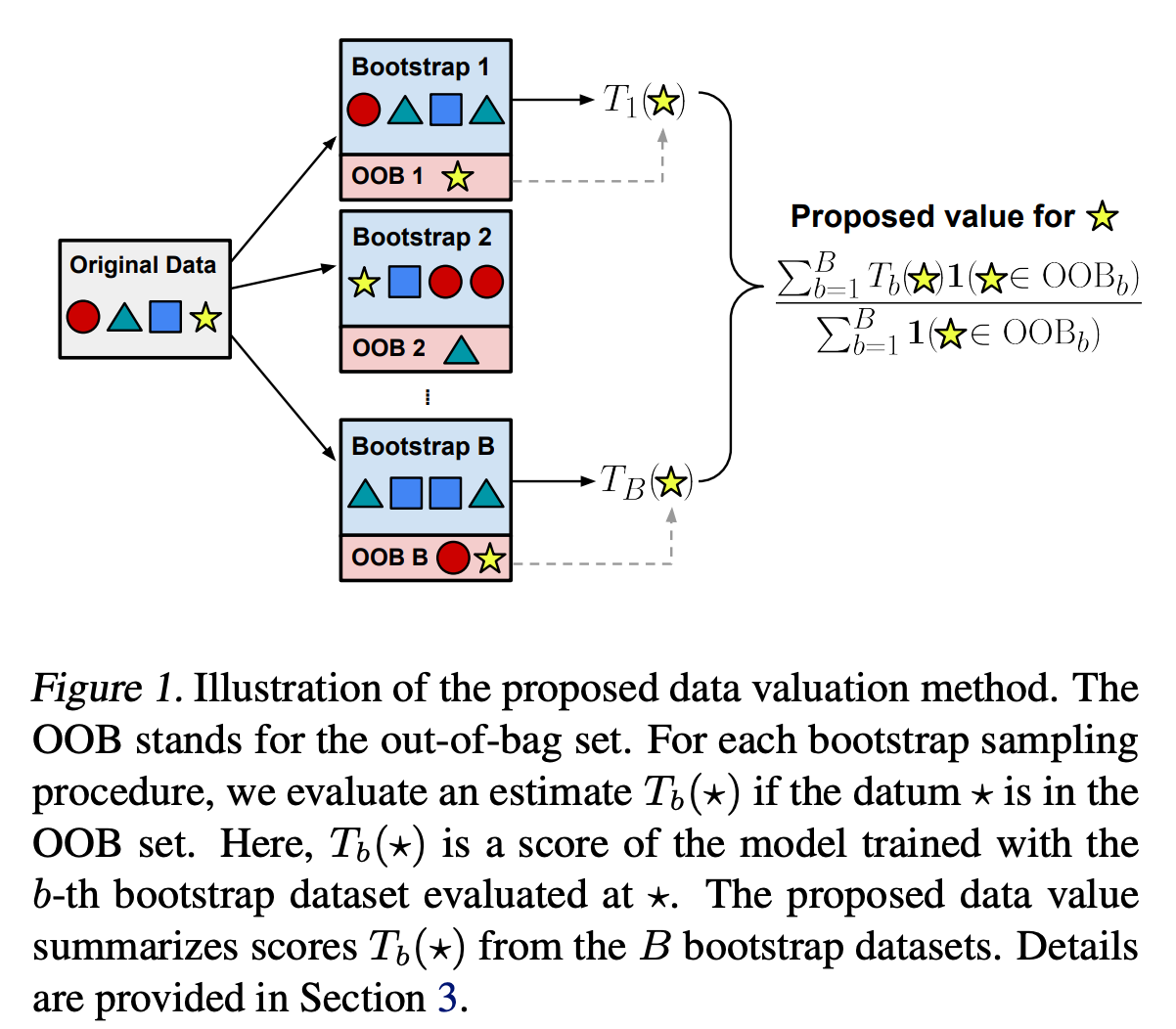
3. Data-OOB
- 랜덤 포레스트의 Out-of-Bag(OOB) 오차 개념을 활용한 데이터 가치 평가 방법이다.
- 각 데이터 포인트가 OOB 오차 감소에 기여하는 정도를 측정한다.
- 앙상블 모델에 특화된 방식으로, 계산이 빠르고 구현이 간단하다.
- 다른 모델 유형에는 직접 적용하기 어렵다는 한계가 있다.
'Naver AI Tech' 카테고리의 다른 글
[주간학습 정리] Week 7 (1) 2024.09.27 [주간학습 정리] Week 6 (2) 2024.09.13 [주간학습 정리] Week4 (0) 2024.08.30 [주간학습 정리] Week 3 (0) 2024.08.23 [주간학습 정리] Week 2 (0) 2024.08.16